|
Becoming AI-Native · Issue #3
|
May 18, 2026
|
|
You can only fix what
you understand
Week 2 in review. Five products, two patterns, and what we noticed about the gap between building and understanding.
|
|
New here?
Sprint 7 is a group documenting AI-native work in public. Every week we ship: one newsletter, one or two blog posts, and some social signals. You can read every issue we've published in the archive.
Browse all issues →
|
|
Hi. This is Sprint 7.
Third letter. Week 2 is done and we're writing this on Monday morning before the week gets going.
If you're new: Sprint 7 is a small group documenting the actual process of learning to work AI-natively. We publish what we built, where we got stuck, and the patterns that carry over week to week.
|
Week 2 in one line
If we had to compress what we learned this week into a single sentence:
|
"You can only correct the AI's output to the degree you understand the idea behind it."
|
|
Five products were in motion during week 2. One member was mapping career values into a tool that helps someone compare what kind of company might fit them. Another was working on a NYC parking sign reader: take a photo, untangle the rules, and see whether parking is allowed now. There was a shared ledger for couples to understand spending together, a career test that compares personal tendencies with company culture, and a private film club manager for screenings, attendance, and votes. The products started in different places, but two patterns showed up across them.
Pattern 1: The app stops being yours the moment you stop understanding it.
One person was building an app that started from the question of changing careers and finding companies that fit them. They had studied the topic before writing prompts. So when Claude went in the wrong direction, they could say, "This is not it. Fix it." That ability to catch the wrong answer came directly from understanding what the right answer was supposed to look like. Without that grounding, the product gradually becomes the model's interpretation of your idea rather than your idea itself.
Pattern 2: Big plan, invisible errors. Phases, visible errors.
The sessions that went well were the ones where the scope was broken into explicit phases. Each phase had a narrow, testable goal. When something broke, the location of the error was obvious. Contrast this with sessions where the full system was handed off in one request: when those sessions produced broken output, nobody could tell which part had gone wrong without re-reading the whole thing. Phase splitting isn't a workflow preference. It's a precondition for being able to fix anything.
The two patterns are the same observation from different angles. Comprehension lets you split work into phases. Phases make errors visible. Visible errors can be fixed. The loop only runs if you understand what you're building in the first place.
|
What we published this week
Outside this newsletter, a few things went out this week.
|
Medium
"The Question I Was Asking Was Wrong"
How the validation question shifted across five products, from "will people pay?" toward "do I understand this well enough to fix what the model gets wrong?"
Read →
|
|
X · Threads
Research workflow (NotebookLM + last30days + insane-search) on X, phase-split debugging in a Threads chain, and the AI-as-amplifier observation.
|
Korean edition of this newsletter is at sprint7ai.stibee.com. Same week, same topics, different entry angle.
|
Where design made the difference
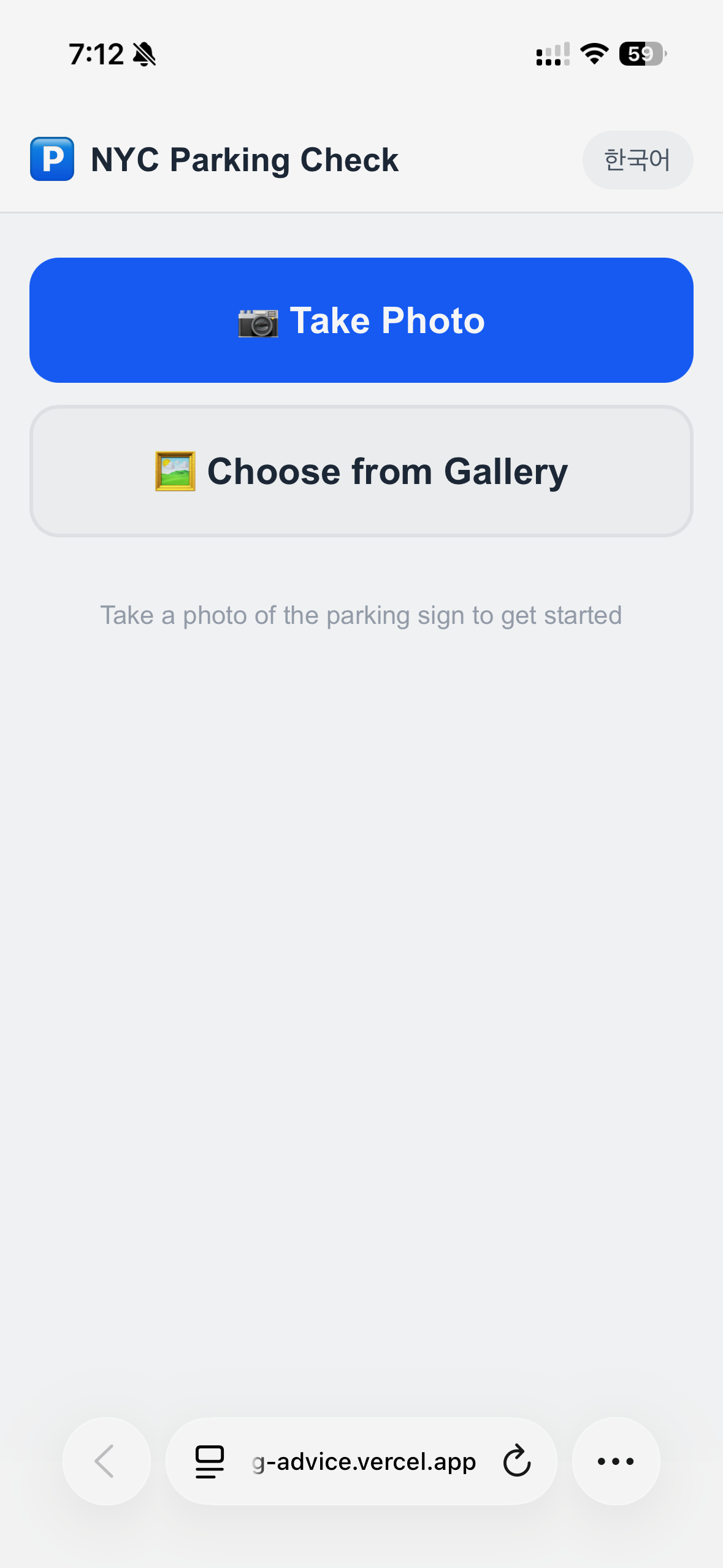
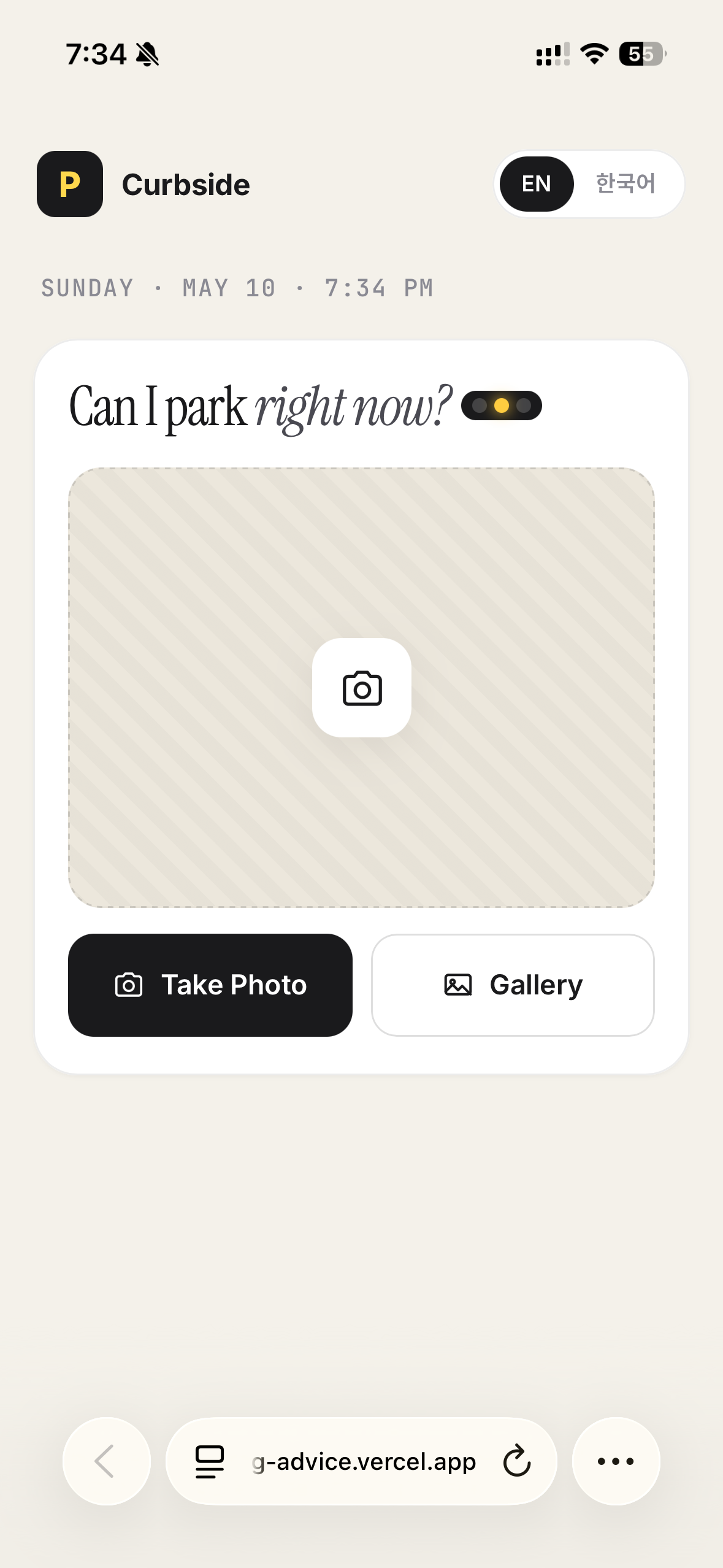
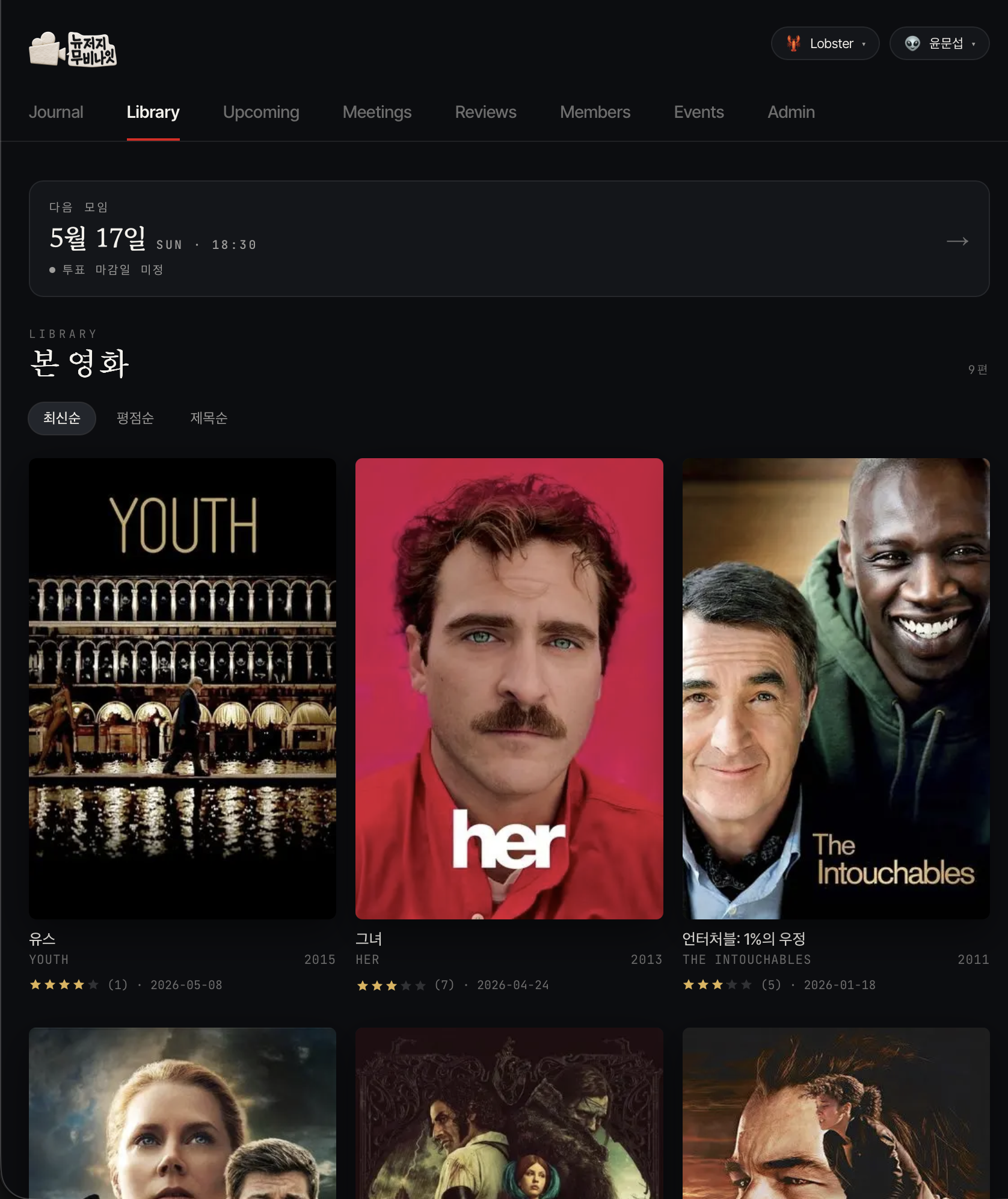
One member shared a side-by-side capture of the same parking app, first built with Claude Code alone, then passed through Claude Design. Another member built a private film club tool and showed how the same functionality starts to feel like a different product once the design tone settles.
These are the four screens from this week. Same function, but a cleaner question hierarchy, sharper button states, and tighter spacing made each one feel more like a product. Design is not decoration. It is the layer that makes the next action obvious.
→ Swipe to see all four screens
|
Three signals from the week
Tools and concepts that came up across builds this week. All within the past 30 days.
|
NotebookLM + last30days + insane-search
A three-tool research stack is forming inside Sprint 7. Each tool covers a different information layer. They don't overlap. Running them in parallel has been the pattern across at least two members' research sessions. @sprint7ai, May 17.
|
|
Popper-style hypothesis testing for ideas
Treat the app idea as a hypothesis. Before building, ask how you'd kill it. One member found this framing via a GitHub resource by David Sweet and applied it during the PRD phase. The framing changes how you evaluate what the model generates. You're looking for disconfirmation, not confirmation.
|
|
On-device LLM as a practical option
Running a small model locally instead of routing everything through a server API is moving from theoretical to viable. It came up as a suggested fix for a multilingual consistency issue in the parking sign reader. Worth tracking.
|
|
Thanks for reading.
The "AI builds it for you" framing gets repeated a lot. What week 2 actually looked like was something closer to this: the model runs faster than you think, surfaces output that looks reasonable, and if you don't understand the idea well enough to evaluate that output, you end up approving things that aren't what you meant. The people who caught problems early this week were the ones who had done the reading.
See you next Monday.
Sprint 7
|
|